Writing arm64 Assembly for iOS

Even as mobile devices continue to become more powerful, iOS developers can still benefit from strategies to optimize their apps for performance. One way to do this is by utilizing low-level assembly code, specifically the ARM64 architecture found in more recent iOS devices. This post will cover how to setup up your Xcode project for this and go over some basics of arm64 assembly for improving performance of Swift apps.
Why?
Generally, you don’t want to do this. But sometimes you need to optimize a particular routine in your app by processing data more efficiently and using the GPU is overkill or not the right tool. In particular, taking advantage of the NEON instruction set allows parallel processing on data which can make your software more efficient.
Setup
You’ll need to create a few files in your Xcode project:
-
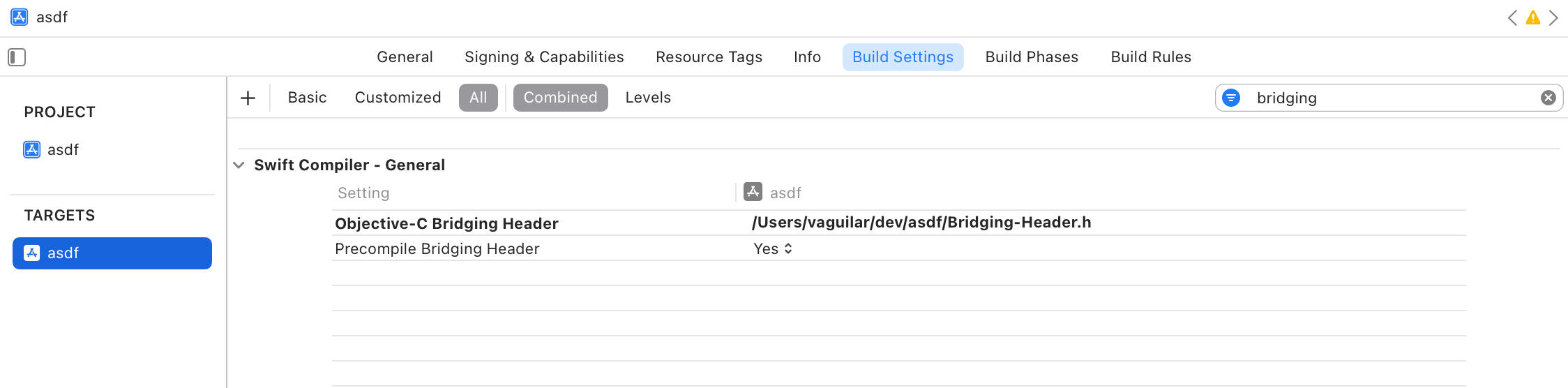
Bridging-Header.h- the Xcode Bridging Header to connect assembly functions to Swift code -
Assembly.s- where we’ll store our assembly routines
Along with these, you’ll need to configure some settings in Xcode to make this work:
- Designate your bridging header file for your target
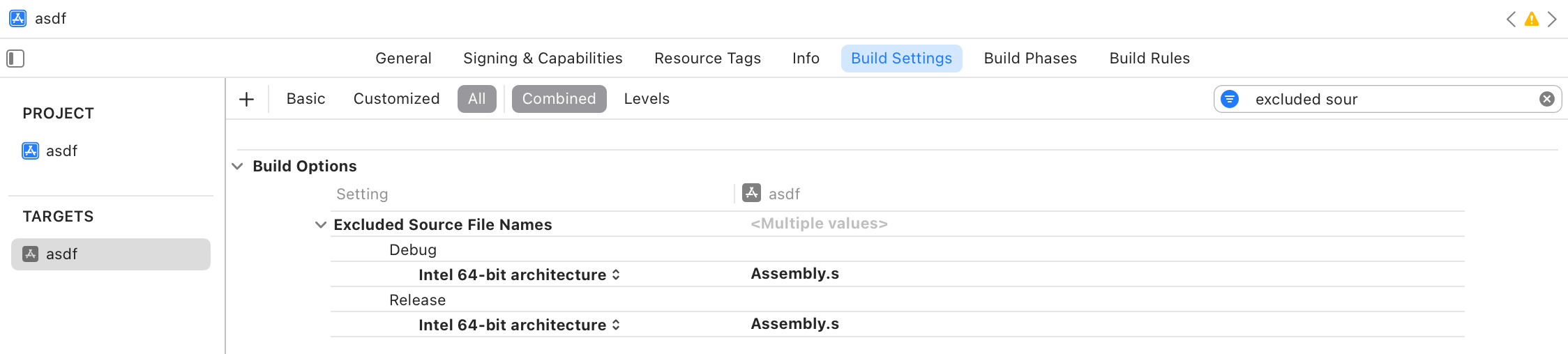
- If your app also builds for other architectures like
x86_64, you should exclude theAssembly.sfor Intel architectures. If not, you’ll hit errors when building all architectures.
A Contrived Example
Let’s say we needed to round millions of floating point numbers. We can write a function to do this that takes two parameters: a pointer to an array of float values and the length of the array.
Assembly
In Assembly.s, we can write a function using NEON instructions to simultaneously round several floating point values. We’ll load 8 floats (8 32-bit values) into v0 and v1 vector registers, use the frintx instruction which rounds 4 floats at the same time, and then store them back to the array buffer. I won’t go into too much detail on how this is set up and what it’s doing, but you can read more about in the attached resources at the end of the post:
.global _fastArrayRound
.p2align 2
// register x0 is a pointer to the array, x1 is the length
_fastArrayRound:
ld1 {v0.16b, v1.16b}, [x0] // load floats into v0 and v1
frintx v0.4s, v0.4s // round floats in v0
frintx v1.4s, v1.4s // round floats in v1
st1 {v0.16b, v1.16b}, [x0], #32 // store them back, x0 += 32
subs x1, x1, #8
bgt _fastArrayRound // jump back to beginning if we're not done
ret
Bridging Header
This should have C function header for your arm64 routine:
void fastArrayRound(float *arr, int size);
And now it should now be available to use in Swift by calling it like this:
fastArrayRound(...)
If you are also compiling for x86_64, you can provide a fallback for this architecture when you want to call our architecture specific code:
#if arch(arm64)
fastArrayRound(...)
#else
// x86_64/other arch fallback
#endif
Performance Metrics
How much faster is this? A naive implementation might look something like this:
func arrayRound(_ arr: inout [Float32]) {
for i in 0..<arr.count {
arr[i].round(.towardZero)
}
}
Benchmarking it on an array of 224 random floats with a simple program:
var arr: [Float32] = (0..<16777216).map{ _ in Float32.random(in: 0...10) }
arrayRound(&arr)
vaguilar@Victors-MacBook-Air src % time ./array_round
real 0m22.938s
user 0m22.537s
sys 0m0.070s
And then using arm64 NEON fastArrayRound function in the previous section:
vaguilar@Victors-MacBook-Air src % time ./fast_array_round
real 0m16.229s
user 0m15.995s
sys 0m0.035s
This results in a ~30% speed up in the program. You can probably optimize this further with other techniques but we can save that for another post.